Window and aggregate data with Flux
A common operation performed with time series data is grouping data into windows of time, or “windowing” data, then aggregating windowed values into a new value. This guide walks through windowing and aggregating data with Flux and demonstrates how data is shaped in the process.
If you’re just getting started with Flux queries, check out the following:
- Get started with Flux for a conceptual overview of Flux and parts of a Flux query.
- Execute queries to discover a variety of ways to run your queries.
The following example is an in-depth walk-through of the steps required to window and aggregate data.
The aggregateWindow() function performs these operations for you, but understanding
how data is shaped in the process helps to successfully create your desired output.
Data set
For the purposes of this guide, define a variable that represents your base data set. The following example queries the memory usage of the host machine.
dataSet = from(bucket: "db/rp")
|> range(start: -5m)
|> filter(fn: (r) =>
r._measurement == "mem" and
r._field == "used_percent"
)
|> drop(columns: ["host"])
This example drops the host column from the returned data since the memory data
is only tracked for a single host and it simplifies the output tables.
Dropping the host column is optional and not recommended if monitoring memory
on multiple hosts.
dataSet can now be used to represent your base data, which will look similar to the following:
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:00.000000000Z 71.11611366271973
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:10.000000000Z 67.39630699157715
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:20.000000000Z 64.16666507720947
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:30.000000000Z 64.19951915740967
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:40.000000000Z 64.2122745513916
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:50.000000000Z 64.22209739685059
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:00.000000000Z 64.6336555480957
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:10.000000000Z 64.16516304016113
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:20.000000000Z 64.18349742889404
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:30.000000000Z 64.20474052429199
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:40.000000000Z 68.65062713623047
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:50.000000000Z 67.20139980316162
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:00.000000000Z 70.9143877029419
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:10.000000000Z 64.14549350738525
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:20.000000000Z 64.15379047393799
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:30.000000000Z 64.1592264175415
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:40.000000000Z 64.18190002441406
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:50.000000000Z 64.28837776184082
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:00.000000000Z 64.29731845855713
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:10.000000000Z 64.36963081359863
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:20.000000000Z 64.37397003173828
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:30.000000000Z 64.44413661956787
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:40.000000000Z 64.42906856536865
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:50.000000000Z 64.44573402404785
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:00.000000000Z 64.48912620544434
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:10.000000000Z 64.49522972106934
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:20.000000000Z 64.48652744293213
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:30.000000000Z 64.49949741363525
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:40.000000000Z 64.4949197769165
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:50.000000000Z 64.49787616729736
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49816226959229
Windowing data
Use the window() function
to group your data based on time bounds.
The most common parameter passed with the window() is every which
defines the duration of time between windows.
Other parameters are available, but for this example, window the base data
set into one minute windows.
dataSet
|> window(every: 1m)
The every parameter supports all valid duration units,
including calendar months (1mo) and years (1y).
Each window of time is output in its own table containing all records that fall within the window.
window() output tables
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:00.000000000Z 71.11611366271973
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:10.000000000Z 67.39630699157715
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:20.000000000Z 64.16666507720947
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:30.000000000Z 64.19951915740967
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:40.000000000Z 64.2122745513916
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:50.000000000Z 64.22209739685059
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:00.000000000Z 64.6336555480957
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:10.000000000Z 64.16516304016113
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:20.000000000Z 64.18349742889404
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:30.000000000Z 64.20474052429199
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:40.000000000Z 68.65062713623047
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:50.000000000Z 67.20139980316162
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:52:00.000000000Z 70.9143877029419
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:52:10.000000000Z 64.14549350738525
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:52:20.000000000Z 64.15379047393799
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:52:30.000000000Z 64.1592264175415
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:52:40.000000000Z 64.18190002441406
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:52:50.000000000Z 64.28837776184082
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:53:00.000000000Z 64.29731845855713
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:53:10.000000000Z 64.36963081359863
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:53:20.000000000Z 64.37397003173828
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:53:30.000000000Z 64.44413661956787
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:53:40.000000000Z 64.42906856536865
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:53:50.000000000Z 64.44573402404785
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:00.000000000Z 64.48912620544434
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:10.000000000Z 64.49522972106934
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:20.000000000Z 64.48652744293213
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:30.000000000Z 64.49949741363525
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:40.000000000Z 64.4949197769165
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:50.000000000Z 64.49787616729736
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:55:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49816226959229
When visualized in the InfluxDB UI, each window table is displayed in a different color.
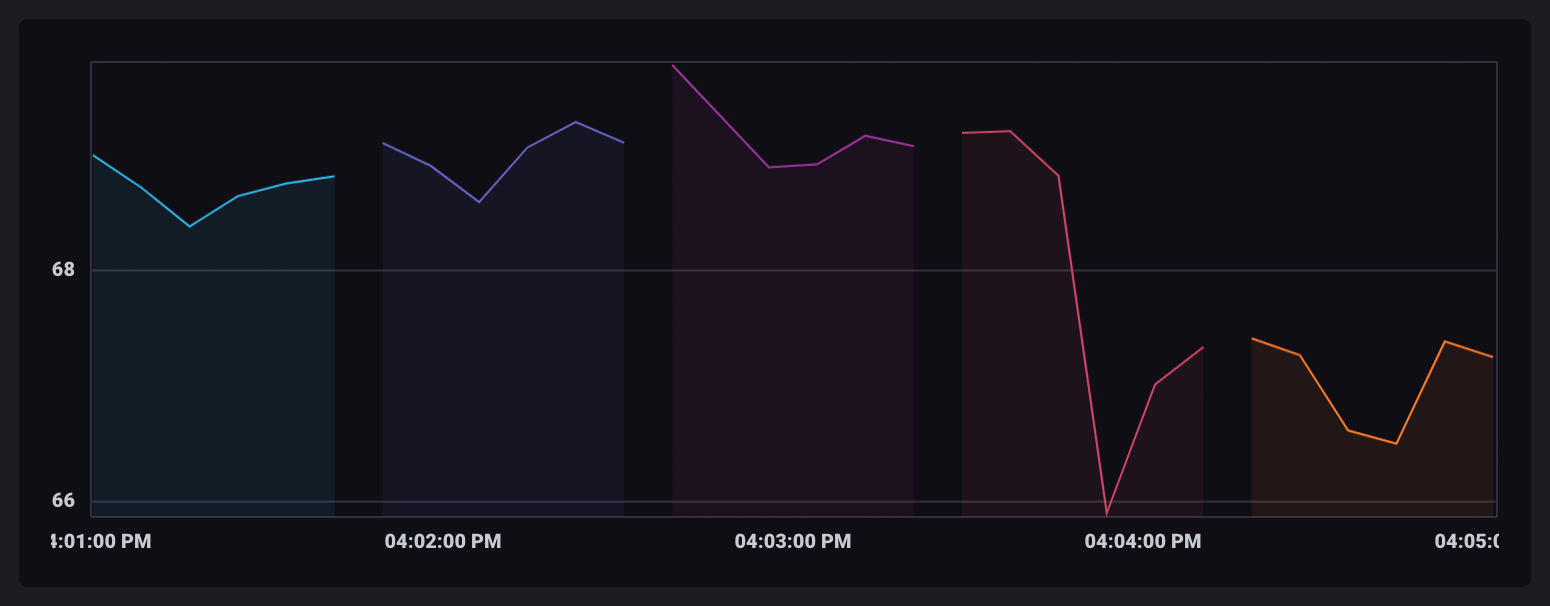
Aggregate data
Aggregate functions take the values of all rows in a table and use them to perform an aggregate operation. The result is output as a new value in a single-row table.
Since windowed data is split into separate tables, aggregate operations run against each table separately and output new tables containing only the aggregated value.
For this example, use the mean() function
to output the average of each window:
dataSet
|> window(every: 1m)
|> mean()
mean() output tables
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 65.88549613952637
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 65.50651391347249
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 65.30719598134358
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 64.39330975214641
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 64.49386278788249
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:55:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 64.49816226959229
Because each data point is contained in its own table, when visualized, they appear as single, unconnected points.
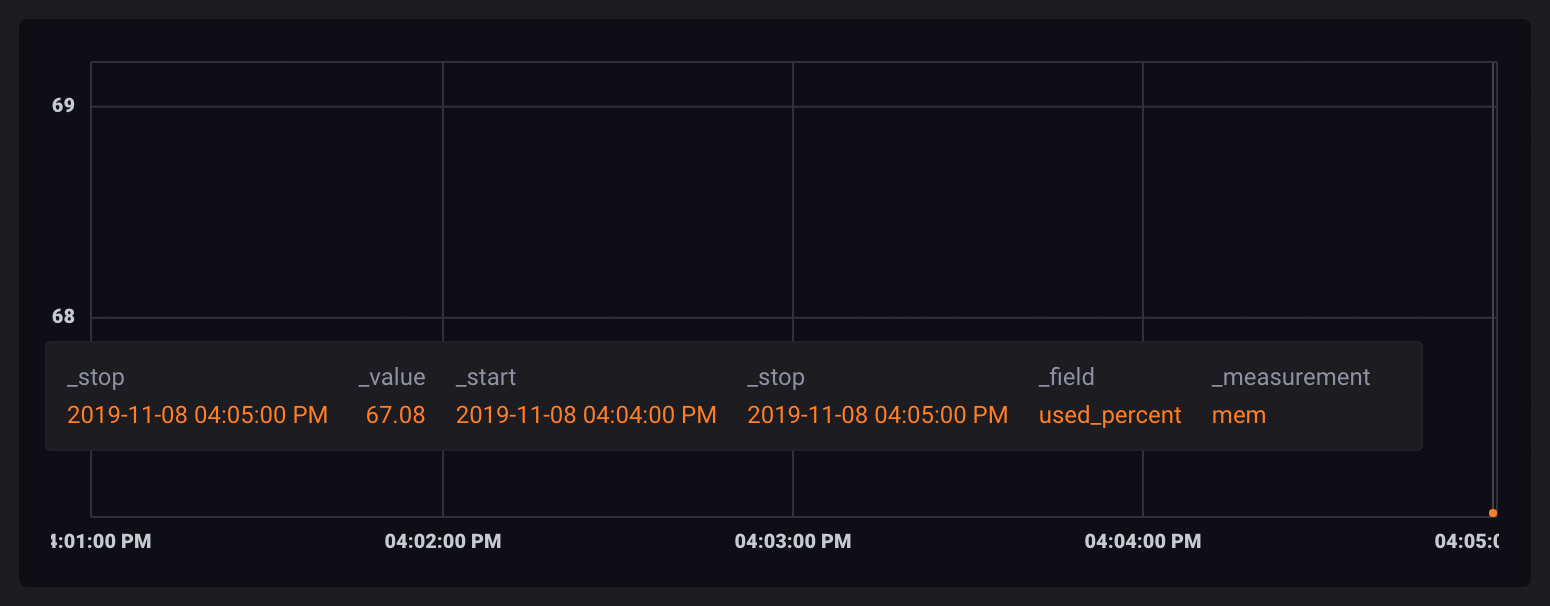
Recreate the time column
Notice the _time column is not in the aggregated output tables.
Because records in each table are aggregated together, their timestamps no longer
apply and the column is removed from the group key and table.
Also notice the _start and _stop columns still exist.
These represent the lower and upper bounds of the time window.
Many Flux functions rely on the _time column.
To further process your data after an aggregate function, you need to re-add _time.
Use the duplicate() function to
duplicate either the _start or _stop column as a new _time column.
dataSet
|> window(every: 1m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
duplicate() output tables
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:51:00.000000000Z 65.88549613952637
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:52:00.000000000Z 65.50651391347249
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:53:00.000000000Z 65.30719598134358
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:54:00.000000000Z 64.39330975214641
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49386278788249
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:55:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49816226959229
“Unwindow” aggregate tables
Keeping aggregate values in separate tables generally isn’t the format in which you want your data.
Use the window() function to “unwindow” your data into a single infinite (inf) window.
dataSet
|> window(every: 1m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
|> window(every: inf)
Windowing requires a _time column which is why it’s necessary to
recreate the _time column after an aggregation.
Unwindowed output table
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:00.000000000Z 65.88549613952637
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:00.000000000Z 65.50651391347249
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:00.000000000Z 65.30719598134358
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:00.000000000Z 64.39330975214641
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49386278788249
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49816226959229
With the aggregate values in a single table, data points in the visualization are connected.
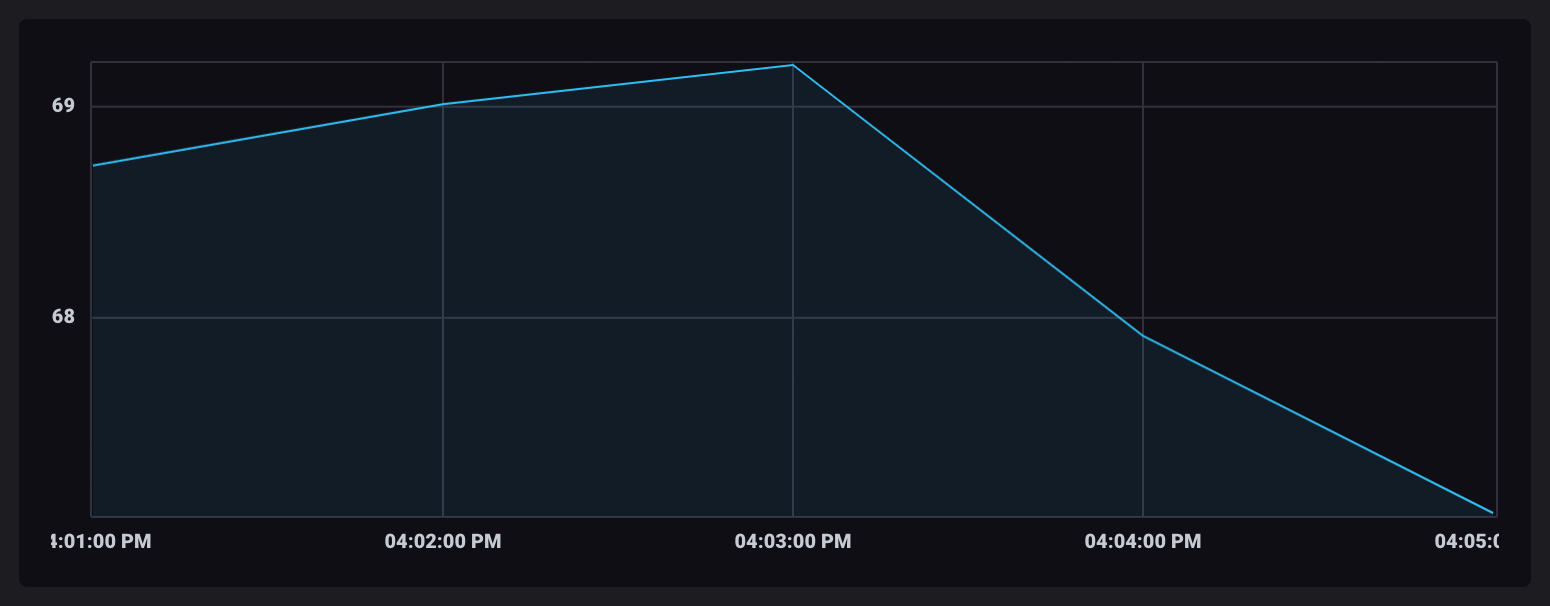
Summing up
You have now created a Flux query that windows and aggregates data. The data transformation process outlined in this guide should be used for all aggregation operations.
Flux also provides the aggregateWindow() function
which performs all these separate functions for you.
The following Flux query will return the same results:
aggregateWindow function
dataSet
|> aggregateWindow(every: 1m, fn: mean)